1)識字率の例
経験科学とデータサイエンスのギャップの検討に入る前に、データサイエンスの特徴を検討しておきます。
最初は、労働生産性の問題です。
義務教育が公共財として提供されるようになった、原因は識字率です。デジタル写真やデジタル録音、デジタル動画などのデジタルマルチメディアが出てくるまで、音声や画像を保存、コピー、転送するコストは非常に高かったので、情報伝達は文字によっていました。
デジタルマルチメディアを社会でどのように活用すべきかが大きな課題です。図鑑のライオンの絵を見るより、動画のライオンを見た方が理解は早いです。現在は匂い、味覚、触角などの情報はデジタルマルチメディアには含まれていませんが、メタバースには含まれてくると思われます。今のところ、「ライオン」のような伝統的な言葉によるインデックスがつけられていますが、今後は、インデックスも変化すると思われます。例えば、「青」と「blue」の違い、「ニワトリ」と「chicken」違いは、個々の画像に対するインデックスのつけ方に違いに反映されます。教科書のデジタル化は、人間の認識構造に合わせてテキストに再構築することに意味があります。実験、実習の一部は、デジタルマルチメディアに置き換え可能です。授業の大半もデジタルマルチメディアに置き換え可能です。そこで空いた時間やスペースに何を入れるべきかを検討する必要があります。
さて、話を文字に戻します。
200年前の日本は、世界で見れば、異常に識字率の高い国でした。
データサイエンスでは、便宜的に正規分布を使うことがあります。これは、言葉で考えると、バイナリーバイアスになりがちなエラーを避ける方法です。
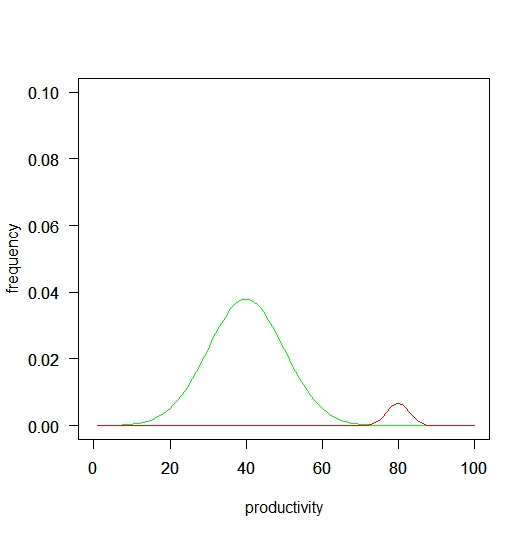
図1は、労働生産性のイメージです。
図1を識字率の説明と仮定します。
緑色の分布は、文字の読めない人です。ここでは、文字の読めない人の労働生産性を40ポイントと仮定しています。
赤色の分布は、文字の読める人です。ここでは、文字の読める人の労働生産性を80ポイントと仮定しています。
縦軸は、相対人口を示しています。
図1では文字の読める人が少なく、文字の読めない人が大半を占めています。
ここで、識字教育をすれば、緑色の分布の山が下がって、赤色の分布の山が上がってきます。
これが、識字教育における労働生産性の効果です。
図1は、識字率以外にもあてはまります。
例えば、英語が読める識字率も同じ構造をしています。
ソフトウェアで、頻繁にバージョンアップされる場合には、日本語のマニュアルは、バージョンアップについていけないので、英語版にたよることになります。この場合、古い日本語のマニュアルよりも、誤訳が含まれていても、最新版の英語マニュアルの自動翻訳の日本語の方が価値があります。マニュアルのどこに必要な情報が記載されているのかを検索するのであれば、通常は、自動翻訳でも十分です。自動翻訳で、ポイントにあたりをつけて、それから、じっくり、英語を読んでいる人も多いと思います。
プログラムコードが読める、数式が読める、楽譜が読めるなども、同じ構造をしています。
楽譜については、一部例外があります。
音楽の場合には、楽譜は実体ではなく、音が実態です。楽譜が読めなかったパコ・デ・ルシア(ギタリスト)のような天才音楽家もいます。作曲家の自作自演の録音や、作曲家の了承を受けて演奏した音楽家の録音には、楽譜に含まれない情報が入っています。
図1を、読むことと書くことに違いとみることも出来ます。
文章を読むことと文章を書くことに間には、大きな能力のギャップがあります。
また、音読できても、内容が理解できているとは限りません。
レストランのオーダーの個数のような単純なものであれば、音読出来れば、内容が理解できていますが、複雑なものになると怪しいです。
緑色の分布は、文章の読める人です。
赤色の分布は、文章の書ける人です。
この場合、識字率とはちがって、文章の読める人を、文章の書ける人にグレードアップすることは容易ではありません。
英語のパラグラフ・ライティングは、論理的な展開は諦めて、結論の最低限の意味だけを確実に通じる文章の作成術です。
パラグラフ・ライティングでも理由を書きますが、極めて簡単な内容しかかけません。
プログラムにつても同様に扱えます。
緑色の分布は、プログラムの読める人です。
赤色の分布は、プログラムの書ける人です。
プログラム言語の種類が多いため、プログラムの読める人けれど、プログラムの書ける人は多数います。
c言語は、古典的な言語で、c言語で書かれたサンプルコードが多いため、これが読めることは、IT技術者のリテラシーの前提になります。一方のプログラムを書くときには、c言語の後継のc++言語を使うか、c言語以外の言語を使うのが普通です。
このように、図1のように全体を2つの正規分布の合成分布と考えると、平均値(1つの正規分布)では、見えなかった点が見えてきます。
2)労働生産性
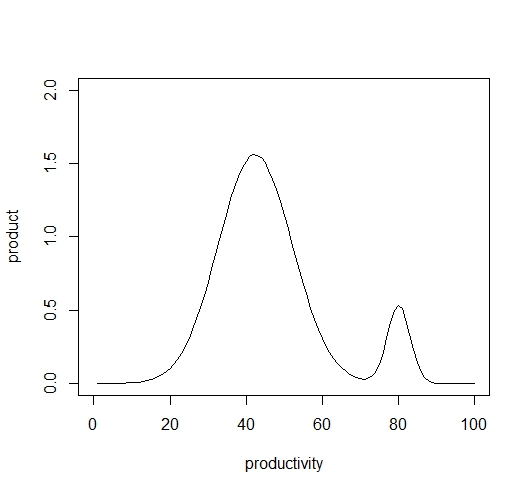
図1は、横軸に労働生産性をとった労働生産性別の人口のヒストグラムになっています。
各ヒストクラムの労働生産性は、横軸になっていますから、縦軸の頻度に、横軸の生産性をかければ、生産性の階層毎の相対生産量が求まります。
図2は、そうして求めた生産量です。
これから、生産量でみると、緑色の分布と赤色の分布の下の面積は、生産性の場合より、差が小さくなっています。
さて、図1と図2の前提条件を説明しておきます。
図1の緑色の分布と赤色の分布の下の面積比は、95:5です。
つまり、生産性上位グループは、全労働者人口の5%と仮定しています。
5%の根拠は次にあります。
(1)情報教育の研修の講師をしたことがありますが、数式からアルゴリズムを展開して、プログラムを自分で書ける人の割合は、10%未満です。
(2)エクセルのユーザーのうち、組み込みベーシックでプログラムを書いている人の割りは、2から5%と言われています。
(3)藤巻 健史氏は、アメリカ経済は、「トップ5%が仕組みを作り、残り95%を動か」しているといっています。
システムをアルゴリズムレベルで、組みかえて新しいシステムの移行する計画を建てられる人の割合は、5%と見れば、大筋は外さないと思われます。
図1の緑色の分布と赤色の分布の生産性分布の平均値は、40:80です。2倍の差になっています。この数字にはに根拠はありません。分かり易い数字で差をつけただけです。
重いものを動かす能力では、年齢と毎日のトレーニングがものをいいます。年齢を揃えた比較では、運動をしている人と運動をしていない人の2つの分布ができると思われます。その場合の平均値の差は、最大でも3倍くらいと思われます。怪我をして全く、物を持ち上げられない人もいると思われますが、少数でしょう。
怪我をした人を除いても、平均値の2倍の差は小さすぎるかもしれません。
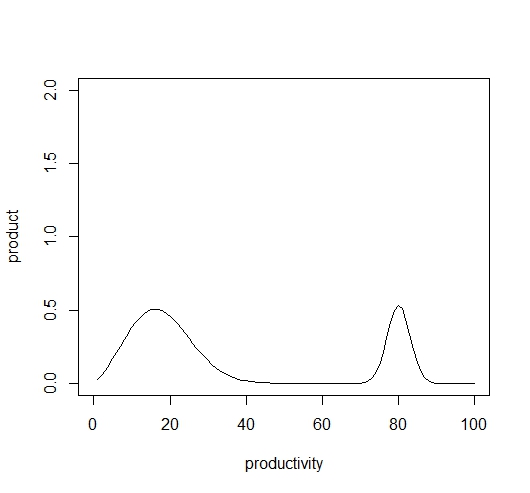
図3は、生産性の平均値を10と80にした場合の生産のグラフです。
この図では、トップ5%の生産は、残りの生産の半分くらいあります。
ここで、ジョブ型雇用で出来高払いの賃金を仮定してみます。
生産の70%が、緑色のグループ、生産の30%が赤色のグループによったと仮定します。人口比は、95:5です。
70/95:30/3 = 0.737:10 = 1:13.6
労働生産性の違いが8倍でしたので、より大きな差がついています。
緑色の下位グループの生産性が重要な疑問になります。
実は、アルゴリズムベースのプログラミングは、数学が理解できない人には、不可能です。ゲームのプログラミングのように、球を動かすのであれば、そのモジュールを呼び出せば簡単にできますが、アルゴリズムを作るには、数学の理解が欠かせません。このレベルのプログラミングができることを、プログラムが書けると呼ぶ場合、緑色のグループの生産性は、赤色のグループの生産性の8分の1より小さく、ほぼゼロです。
3)パラダイムと生産性
緑色の下位グループの生産性が重要な疑問になるのですが、以下では、この差が、パラダイムによって起こる場合を考えます。
(1)経験科学のパラダイム
人文的文化(経験科学)のパラダイムでは、緑と赤の分布の差は量的なものです。例えば、識字率を考えても、全ての漢字を読める人はいません。一方、文字を1つも読めない人も稀です。
つまり、緑と赤のように、分布が2つに分かれることは想定しません。
大学の入学試験では、偏差値が問題になりますが、これは分布を正規分布に置き換えているので、偏差値が当てはまる場合には、2こぶの分布を考える必要がないことを意味しています。
(2)理論科学・計算科学・データサイエンスのパラダイム
科学的文化(理論科学・計算科学・データサイエンス)のパラダイムでは、仮説の正しさは、データに基づく検証で行われます。検証をクリアできなかった仮説は、破棄されますので、価値はゼロです。
数学の入学試験で、解答用紙に計算過程が書かれていて、最後の方で、計算間違いをして、正しい解答に到達しない場合には、部分点をもらえることがあります。
しかし、これは、例外で、数学の試験では、解答が間違って入れば、原則零点です。
白紙の答案と、間違いを書いた答案はどちらも零点になります。
間違いを書いた努力が評価されないのは、白紙より努力しているので、不公平に見えますが、科学的文化では、検証をクリアすることが価値の基準なので、努力は評価されません。
検証をクリアできた仮説は、ひとつなので、科学的文化でも、緑と赤のように、分布が2つに分かれることは想定しません。
(3)ギャップの課題
以上の考察から、人文的文化の人は、緑色のような緩やかな確率分布を想定していて、科学的文化の人は、赤色のような集中的な確率分布を想定しているように思われます。
人文的文化の人は、頑張れば誰でも何とかなると考えます。科学的文化の人は、頑張っても、仮説なダメな時は、アウトだと考えます。
プログラミングは、科学的文化の産物です。以下に大量のプログラムを書いても、カンマとピリオドを間違えて、計算結果が間違ってしまえば、アウトカムズは零点になります。もちろん、バグがゼロのソフトウェアはありませんが、根幹部分に、バグがあった場合には、ソフトウェアの存在価値はなくなります。
スノーは、二つの文化の間には、ギャップがあると言いました。
これは、人文的文化の人は、緑色の分布を想定することに対応します。同じようなレベルの能力の人が集まって協力すれば、アウトカムズが出ると考えます。給与は春闘のレベルアップで評価できると考えます。
ギフテッド対策は、障碍者に対する社会順応プログラムと考えます。
科学的文化の人は、赤色の分布を想定することに対応します。高度人材に能力発揮の場をつくることが、重要と考えます。
ギフテッドは、高度人材になりうる金の卵だと考えます。
図3の生産性ギャップは8倍です。科学的文化で考えれば、プログラミングでは実際のギャップははるかに大きくなります。それは、COCOAのように、正しく機能しないプログラムは、零点(生産性がゼロ)と評価するためです。
NTTデータは、GAFA予備校と呼ばれ、人材の流出がとまりません。
人文的文化の人は、これを日本企業からの一部の人材流出であり、出来れば止めたいと思っているかも知れません。
科学的文化の人は、問題は、上位5%の赤色の分布なので、高度人材流出は、ほぼ致命傷であると考えます。
パラダイムギャップが、この2つの見方の違いにあり、それは、スノーの指摘したギャップになります。
引用文献
この国では「真面目に努力する人」ほど損をする…日本の「天才」が次々と海外へ流出してしまう根本原因 President 藤巻 健史
https://president.jp/articles/-/64767